
Table of Contents[Hide][Show]
Most professional SEO Audits cover multiple numbers of critical checkpoints that range from accessibility and indexation essentials to penalty audits and even SERPs or competitor analysis, depending on scope and budget.
In this article, I aim to highlight specific areas that, in my opinion, should get a bit more attention.
These areas or checkpoints can be less common yet essential to avoid SEO disasters, particularly for websites targetting International markets:
- Inconsistent url casing
- Inconsistent encoding on url formations
- Incorrectly formatted robots.txt files
- Assessing TTFB (Time to First Byte)
- CDN optimization
- Chain redirects or Redirect Loops
- Multi XML sitemaps
- Semantic mark-up
While some technical SEO audits I’ve been able to see and review were pretty decent and well researched, some others, despite them being expensive and carried out by sizeable known SEO agencies, lacking in depth or focus.
This happens as frequently SEO audits are carried out based on the same usual checklist template rather than being tailored to the needs of the client.
The list below is an attempt at identifying uncommon points covered on templated SEO audits, yet essential to complex large websites:
1. Inconsistent url casing
How often do you hear the term ‘canonicalization’. It’s a common term used by SEOs in SEO and can be applied to many different contexts, most revolving around the idea of ‘duplicate content and how to avoid it’.
This is where establishing a strategy to define urls is critical, and in particular, deciding on the casing is very important. In doing so, you will avoid having to patch things up with rel canonicals, 301 redirects, and other hacks in the future.
Let’s take a look at these two scenarios for urls:
1. /this-type-of-url
and
2. /this-Type-Of-Url
Both are valid, and both do exist. But you need to set foot on one and make it law. Having both approaches and allowing URLs to be displayed simultaneously is not the best practice.
In fact, forcing lowercase is becoming more the ‘defacto standard’ these days.
So long as the rules for the url formations are established from the beginning and make it set in stone, it’s fine.
For example, some teams establish that only nouns in urls would have first letter capitalised, while others may have decided to capitalise every initial letter in a word, and yet others go with ‘all lowercase as a rule with no exceptions‘.
I personally prefer the latter and that’s the option I always go with and recommend. If you are working on an SEO inhouse role, you need to set of rules that would define how the URLs will be set up.
Why is this so important?
Because if you don’t establish the url strategy, the problem starts to get out of hand when:
- Inbound links start pouring with the wrong syntax on urls, eg: capital letters everywhere instead of just the first letter
- internal linking point, due to some flaw, to the URL with incorrect syntax
This then starts becoming a duplicate content realm.
All this can be avoided by strictly defining how the system should deal with incorrect url formations.
For example, a typical url syntax plan that I’m keen on and almost always push for can be:
- all urls in lowercase
- No trailing forward slashes allowed
- dash ( – ) symbol will replace the white space in between words
From those three rules, you could create what I have always called internally as: the URL Golden Rule of 3 when I worked as an in-house SEO. Still today I call it that way when I build SEO guidelines and internal SEO policy documentation for clients.
But that’s not enough. If we want to avoid deviations from the above rules, we should specify stability-driven code rules :
- Lowercase urls as a must
- Programmatically, the platform reverses any instance of capital url onto lowercase.
Eg, url: /rainy-days-are-over if you try typing it as : /rainy-days-are-Over
the system will automatically revert onto: /rainy-days-are-over via 301 redirect
This unique feature works as a shield against duplicate content, as it minimizes the chances that someone may link to use with the wrong syntax. So this means if someone links to the site with a capital letter by mistake, the system automatically reverts to lowercase.
See where I’m going? Unless these prevention systems are implemented to help minimize potential misuse of the URLs, their integrity will always be on the line. I rarely see advice like this on SEO audit reports in the form of actionable recommendations.
2. Inconsistent Encoding on url formations
When the website deals with non-Latin characters or special characters, it is essential to decide on the right strategy for url encoding. Is the whole product name going to be encoded, even spaces? or will space be replaced by a dash as an exception or by an underscore like Wikipedia does? Does the rel canonical url need encoding, too? Are there inconsistencies in the way encoding has been performed?
This is quite a technical topic that’s often a must to review as part of an audit exercise on multilingual websites displaying names with accentuations, non-Latin characters (eg: Cyrillic) or special characters.
This is a matter that understandably requires thought, consultation, and patience to get right, so I can see why it is often just superficially mentioned throughout audits, but it does deserve due consideration and assessment. The decision should be documented and if possible, included in a more overarching strategy document such as the ‘URL strategy’, or ‘URL Policy’ document, or ‘SEO Strategy’ for the matter.
The right questions to ask in the framework of an audit are:
- What parts of a url are we going to encode (full url or just the database-powered part of it)?
- Is there also transliteration to do?
- What encoding system are we going to use?
For example:
- The ampersand character (“&”) should be encoded as “&” as it’s a special character. The same should go for the rel canonical url, it should appear encoded.
- The accented “é” in some European languages like Spanish or French should be encoded as “%C3%A9”. Eg: “développement” in French
This encoding is critical for websites that display database-powered products or services. For example, E-commerce websites deal with listing categories that show products in different languages. Or Job board websites are boasting jobs containing technical names with special characters.
Take for example, the C# developer jobs results on this French jobboard website: www.lesjeudis.com.
https://www.lesjeudis.com/metiers/backend/d%C3%A9veloppeur-c%23
The actual jobtitle for those results is ‘Développeur C#’ where the symbol # is encoded as ‘%23‘ and the accented French letter ‘é‘is encoded as ‘%C3%A9‘
Why delve into this kind of hassle?
Well, they have had to encode the sharp symbol that accompanies the letter ‘C’; otherwise, the results would display job offers for Developers in C programming language instead of C sharp (#) .
https://www.lesjeudis.com/metiers/backend/d%C3%A9veloppeur-c
The actual job results would be different as those two programming languages (C vs C#) are different too.
It is essential to get involved in this kind of discussion with the development team as the decisions will impact your onsite SEO plans and the offsite SEO too.
Url encoding, for certain websites where the key content types are database-generated dynamic results, is vital as it will help you avoid a whole host of issues in the future.
Unicode or UTF-8 encodings are safe choices since you can use a single encoding to handle almost any character you will likely encounter. This greatly simplifies things. Deciding on a system for url encoding can help avoid a whole host of issues in the future.
Read more about url encoding here:
https://www.smashingmagazine.com/2012/06/all-about-unicode-utf8-character-sets/
http://www.unicode.org/standard/standard.html
3. Incorrectly formatted Robots.txt files
The robots.txt file is a text file intended for search engine bots or any bots visiting the site. In principle, bots start exploring websites by looking for the robots.txt file at the site’s root.
By looking at the directives in the robots.txt file, search engine robots can specify which pages or content paths can or cannot be indexed. Bots do not always obey those directives, but there is still value in defining the structure of a robot’s file.
For an SEO consultant performing a technical audit, auditing and assessing whether a robots.txt file contains the proper directives is not easy. It should be carefully carried out, allowing sufficient time to consider every aspect of the site architecture.
The way I usually advise on the setup and configuration of the robot’s file is by
- making small annotations of the different website paths throughout the audit.
- Noting down parameters, filters, and fractions that should not be crawled
- I should have added enough intel to be able to advise as to the most suitable config for the robots.txt file.
One needs to have first-hand experience of the website structure and its features, such as faceted navigation, pagination, etc, before one can advise on a suitable configuration for the robots.txt file.
Technical SEO audits are often delivered without much input on the robots.txt file other than general syntax corrections. grab image too
While it is good correcting the syntax and ensure that UTF-8 is used, advising on the correct configuration for the robot’s file is critical to help maximize crawlability on the site in question. Don’t let robots crawl more than they should.
I have seen audits where great advice is given as to the need to deindex content deemed as duplicated or thin (eg: e-commerce urls boasting appended parameters), but then no advice is provided to help declutter the robots file or even set it up properly with an eye on the taxonomy of the website.
3. Assessing TTFB (Time to First Byte)
Google recommends a Server response time under 200 milliseconds. People want fast websites, and they get frustrated when waiting until the page is downloaded. Therefore should TTFB be a must to cover in technical seo audits?
I do not intend to cover entirely the subject of Website speed touching all server/client side factors. But I feel that TTFB has a lot of weight in the overall paradigm of Website speed.
The question would be: how long does the browser wait before receiving its first byte of data from the server? That critical ‘wait’ state should ideally be optimized below 200 ms. I’m not proud of that score of 662.4 on my website.
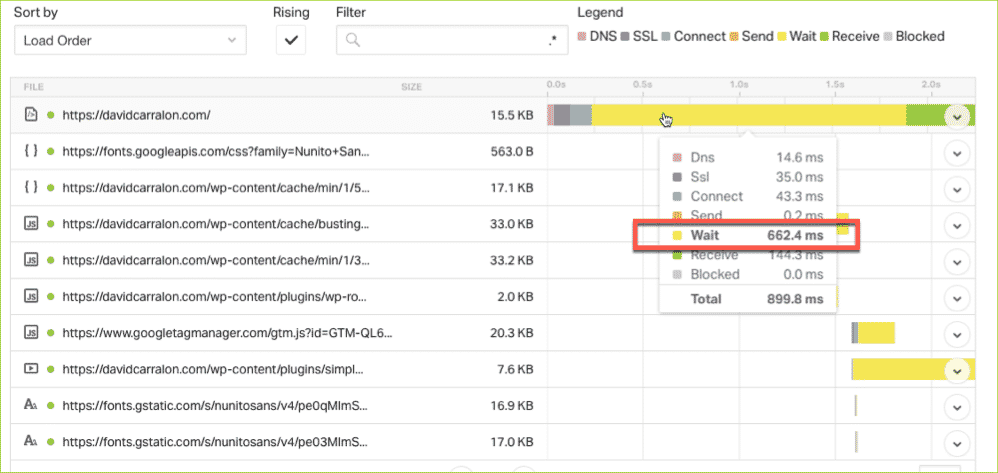
So, where is the bottleneck in there?
Let’s summarise how TTFB takes place in three easy steps:
A. Request to server processing: on every website visit, the client(browser) has to request the server. This request can be fast or slow based on several factors. One of them is the speed of the DNS lookup. Are you using the DNS service provided by your domain name or a premium one? this can make a big difference in delivering a faster request to the server.
You can dramatically improve DNS lookups and load time by moving as many resources as possible to the CDN provider. Yet this is rarely mentioned/covered on technical SEO audits, despite seeing large counts of resources, eg: multimedia content often hosted by the website server itself.
B. Server processing: This is the part where the server has to deal with things like database calls, caching, parsing of 3rd party scripts, and code quality. Server resources play a role here: server processing power, memory, and ability to perform compression (eg: gzip).
This is where having a good solid host can really make a difference. Some hosts claim to have high-speed servers, but they don’t. At some point, moving one of my affiliate sites from WPEngine onto Kinsta saw a speed increase of over 125%.
If your site is running WordPress there are plenty of good options today. Even if you are on a budget, you should be able to find good WordPress hosts.
I see websites backed up by solid well-established businesses running even with VC help, but being hosted in unresponsive or less-than-ideal hosting solutions.
C. Server response to client: again in here having a good host counts too as the network used by the server to send the response has to be fast. This is not to mix with the client’s internet connexion, wifi issues, etc, which would also affect the TTFB, but it’s out of scope here.
In short, assessing how robust the server is, the CDN set up and the effectiveness of the DNS lookup are key things that can dramatically affect overall website speed. These areas should genuinely be included in a technical SEO audit.
4. CDN optimisation
Content delivery networks have a lot to do with the site’s overall performance in search, especially if we are looking at a website with an international reach. Yet, CDN auditing is rarely covered in SEO audits.
CDNs (Content delivery networks) boast the ability to improve SEO in many ways:
- Accelerating page webpage load time across the globe. Webpage Loading time is an essential criterion for SEO. CDNs decrease the webpage’s response time and therefore improve their loading speed
- Decrease the image size sent to the user whenever needed depending on the device.
- Keep stability at times of heavy traffic to the website.
- help reduce the number of server calls
In short, CDNs can be highly beneficial to websites with high traffic levels or sites with geographically dispersed traffic.
However, there are risks associated with CDNs too.
- 1. Misconfigurations of CDN But be careful when installing your CDN: do it cautiously or seek the help of a professional. If you do not install it correctly, it will damage your SEO and your user experience.
- 2. The CDN provider may not have servers in some of your company’s locations. Your customers will then experience Latency and more extended downtime and user experience will be affected.
CDN setup and configuration, as well as possible interference with other aspects of the web architecture, should be audited in the same way as other elements.
5. Chain redirects or redirect loops
This often is often more visible in SEO audits, it’s a must, but I have still seen audits that did not address adequately the different types of chain redirects, or perhaps chain redirects were acknowledged but redirect loops were left aside.
They are two other things, and both contribute primarily to wasting crawl time on site.
Chain redirects can be caused by development changes made to the internal link structure, or by renaming urls or perhaps platform migrations. It is worth assessing properly how severe the matter of chain redirect is throughout the technical SEO audit and advising on prioritization accordingly in the list of recommendations via an audit report.
6. XML Multi-sitemaps
What can be better than a sitemap that acknowledges the taxonomy of the website? A cluster of xml sitemaps comprised of identifiable child sitemaps that represent each of the critical categories or sections of a large website is like a treasure map to indexation success.
XML multi-sitemaps act as a roadmap for diagnosing indexation issues, bloated sections or even bloating in the index itself. Using xml sitemaps and matching them against content already in the index presents a phenomenal tool to help troubleshoot or optimize crawlability and indexation.
Let me clarify: I do agree that sitemaps will not give you an SEO boost, but they will help you get indexation visibility across the horizon to improve your technical SEO strategies. These xml files in combination with crawling data and log file data, can massively inform your SEO to help you establish the next big move.
XML sitemaps get a lot of criticism, often unfairly called ‘useless’, yet they are a handy SEO tool, in my opinion. I have used them to good effect in my career as an SEO, and today I still use them to diagnose, test and improve technical SEO.
More often than not, if the website being audited is over 5K-6K urls, I think there is already enough justification to recommend splitting the xml sitemaps logically into sensible topics, sections or categories. But instead, audits usually just kind of recommendations to have an xml sitemap, or if one is present, this is ticked as if nothing else is to be done.
6. Semantic mark-up
Despite industry-available advice to prioritize structured markup and search engines like Google encouraging webmasters to embrace it, there is still little adoption of structured data today, especially by big brands.
The main goal for structured data is to declare specific elements in the websites’ HTML to help the search engines better understand the content: video, images, ratings, events information, recipes, organization information, job offers.
Read Google’s guidelines for use of Schema structured data and 3rd party resources like Moz’s series on structure data for seo to start getting acquainted with it.
There are three different types of search structured data as part of the Schema.org protocol :
- JSon-LD
- Microdata
- RDFa
However, other types of structured mark-up exist, such as the DublinCore initiative, Facebook Opengraph, and Twitter cards.
In some verticals, this is huge, to the point that unless you implement structured data effectively, you will lose out big in the race to be visible. For example, to rank on the ‘Google for Jobs’ boxes, every individual job posting needs to follow strict Schema parameters either with Json-ld or microdata.
Here’s an example:

Pop over to Merkle to get your schema code automatically generated.
The benefits of implementing marketing up at scale on large website networks are clear. However, this is still today something not fully embraced by large organizations, either due to a lack of internal knowledge, resources, clumsy old CMS, or other corporate SEO impediments.
Here are some tools that you can use to help validate your markup data:
1. Google’s Structured Data Testing tool: https://search.google.com/structured-data/ testing-tool/u/0/
2. Rich result test (Google): https://search.google.com/test/rich-results
3. Validation tool for Bing: https://www.bing.com/toolbox/markup-validator
Researching structure markup feasibility and making recommendations for its implementation if scope exists, should be included in technical SEO audits.
Conclusions
Sometimes though, critical insights on an audit report can be missed as the auditor hasn’t really spent enough time understanding how the business works and how the website delivers against the business objectives. Internal knowledge about the company can really help formulate better recommendations upon the technical SEO audit exercise.
Whatever use you make of the report and the recommendations, it is advised to find an SEO Consultant that can work with your technical teams to implement the recommendations in a way that’s efficient and always looking at the 20/80 rule: trying to achieve 80% of the results investing 20% of time & resource.
you may want to read one of my best pieces on technical audits: “How to do a technical audit effectively in 10 steps“.
Updated: 5 April 2023
 How to Do a Technical SEO Audit Effectively in 10 Steps
How to Do a Technical SEO Audit Effectively in 10 Steps
Leave a Reply